2026 李弘毅課程-加快語言模型生成速度

在語言模型(LLM)的應用中,推論(Inference)階段的文字接龍過程往往是效能瓶頸。為了讓模型生成得更快,我們必須優化其核心——Transformer 的 Self-Attention 機制。本教學將介紹兩種核心優化技術。
第一部分:Flash Attention —— 克服硬體搬運瓶頸¶
Flash Attention 的核心並非改變計算結果,而是優化 GPU 底層的資料存取邏輯。

1. 硬體背景:倉庫與工作台¶
- HBM (倉庫): GPU 儲存資料的大型空間(如 A100 的 80GB 記憶體),但存取速度相對較慢。
- SRAM (工作台): 靠近運算單元的小型高速緩存。運算極快,但容量非常有限(僅約十幾 MB)。
- 瓶頸: 計算本身很快,但頻繁地在「倉庫」與「工作台」之間搬運資料(如 Attention Weight)會拖慢整體速度。
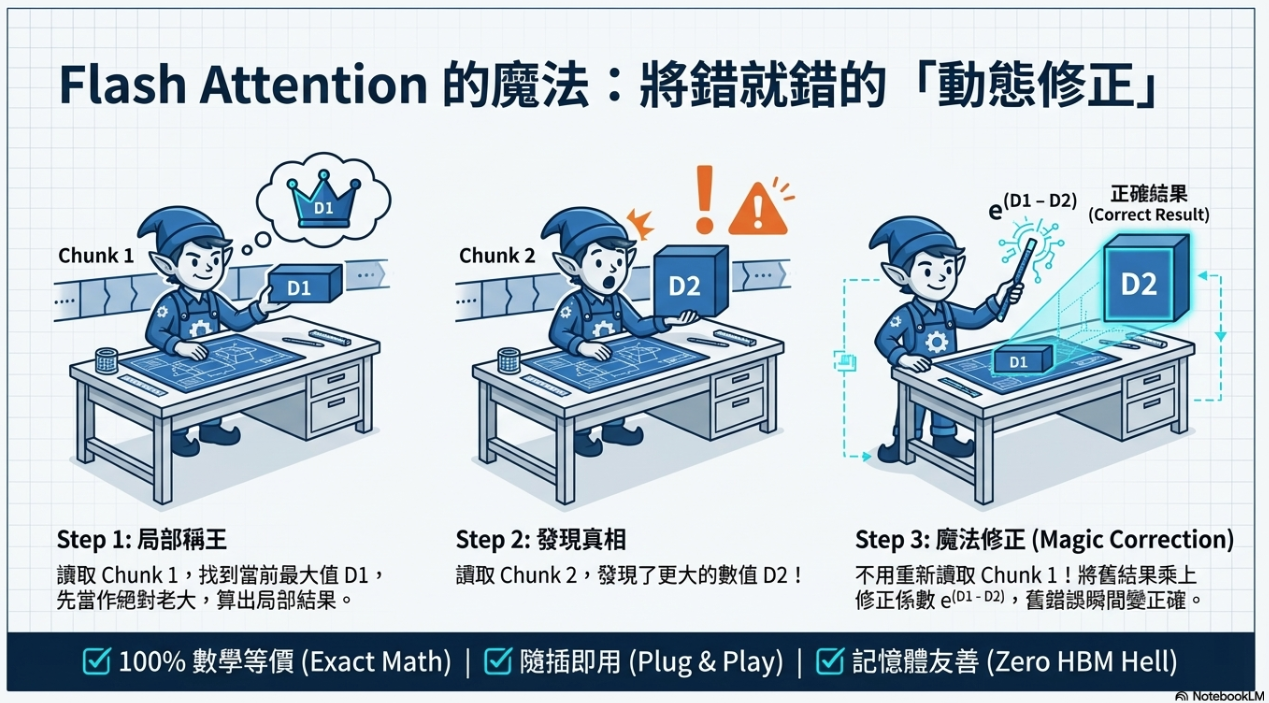
2. Flash Attention 的解決方案¶
- 分塊計算 (Tiling/Chunking): 將長序列切成小塊(Chunks),使其能放進 SRAM 進行運算。
- 線上 Softmax (Online Softmax): 透過數學技巧(乘上指數修正項),在處理每一塊資料時即時修正之前的數值,無需等待讀取完整序列即可算出正確的輸出 $O$。
-
優勢:
-
不改變結果: 它不是近似值,算出來的東西與原始 Attention 完全一樣。
- 隨插即用: 無需重新訓練模型。
- 顯著加速: 在長序列下(如 4096 tokens),可達到 8 至 9 倍 的加速效果。
第二部分:KV Cache —— 避免重複運算¶
在文字生成(Decoding)過程中,每產生一個新 token 都需要考量過去所有的資訊。
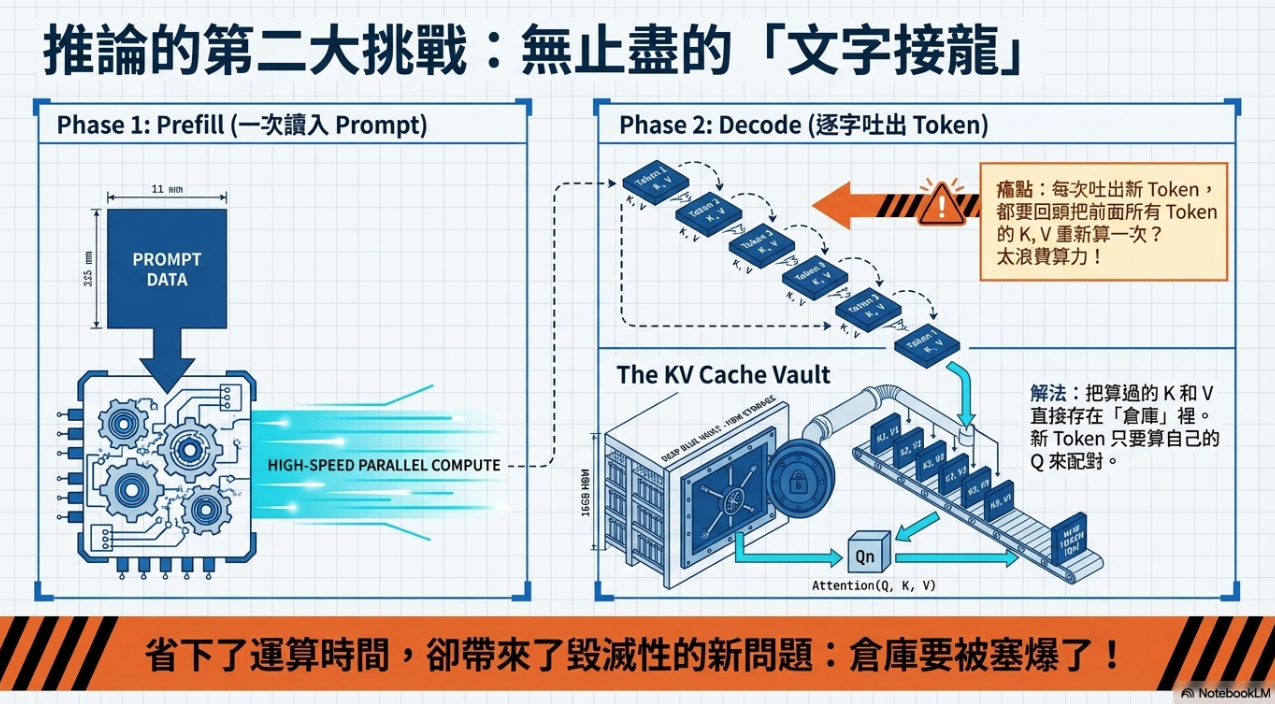
1. 核心概念¶
- 重複計算的問題: 為了產生下一個 token,模型如果不做優化,每次都要重新計算舊 token 的 Key (K) 與 Value (V) 向量,這非常浪費時間。
- 解決方法: 將計算過的 K與 V 存入「倉庫」中,下次只需計算新 token 的 QKV 並與快取中的資料運算即可。
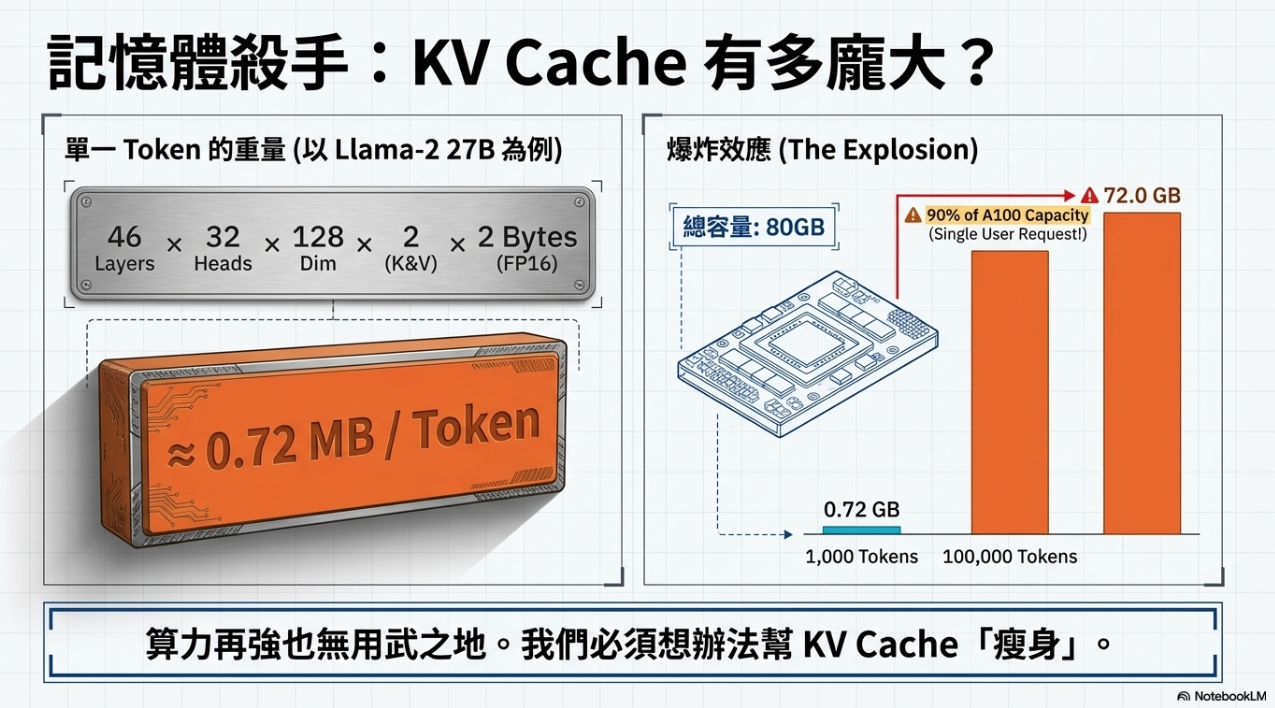
2. 空間挑戰¶
- KV Cache 會隨著序列增長而迅速佔用大量顯存。例如 Gemma 2 27B 模型,單一 token 的 KV 就需約 0.72MB。
- 當序列過長時,原本巨大的倉庫(HBM)也會被撐爆,導致 Out of Memory (OOM)。
第三部分:優化 KV Cache 的進階技術¶
為了減少 KV Cache 佔用的空間,研究者提出了多種變體:
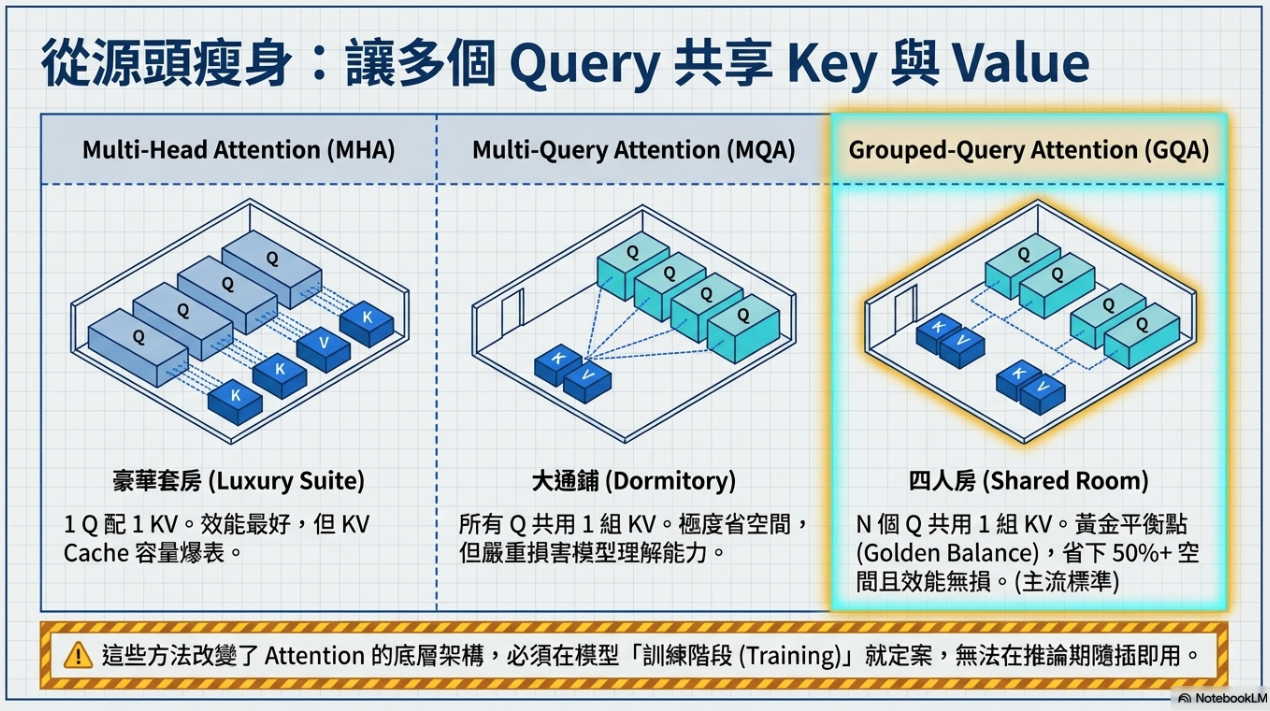
1. 改變 K、V 的組數(架構優化)¶
- MQA (Multi-Query Attention): 所有 Query 共用一組 K、V。雖然省空間,但會損害模型能力。
- GQA (Grouped-Query Attention): 多組 Query 共用一組 K、V,在效能與空間中取得平衡,廣泛用於 Llama 與 Gemma。
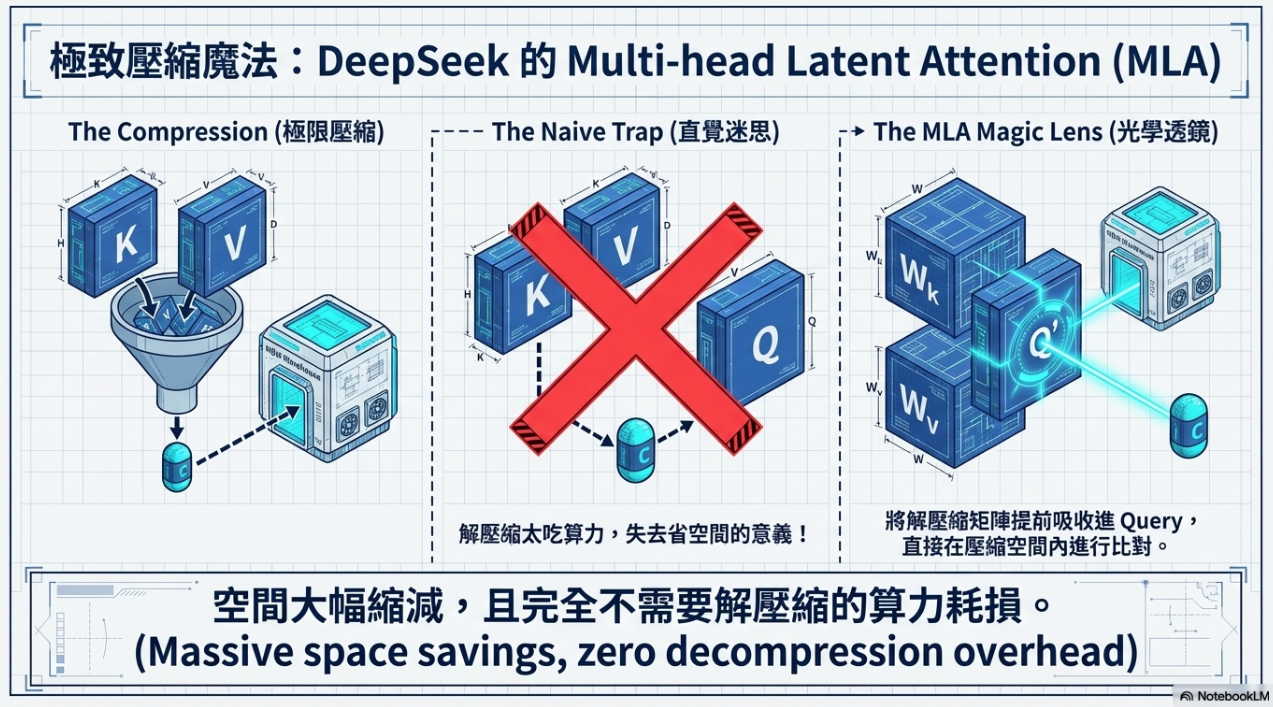
- MLA (Multi-Head Latent Attention): 將 K、V 壓縮成低維向量。神奇之處在於,模型可以在不解壓縮的情況下直接在壓縮空間進行運算,節省大量資源。
2. 改變 Attention 範圍或清理快取¶
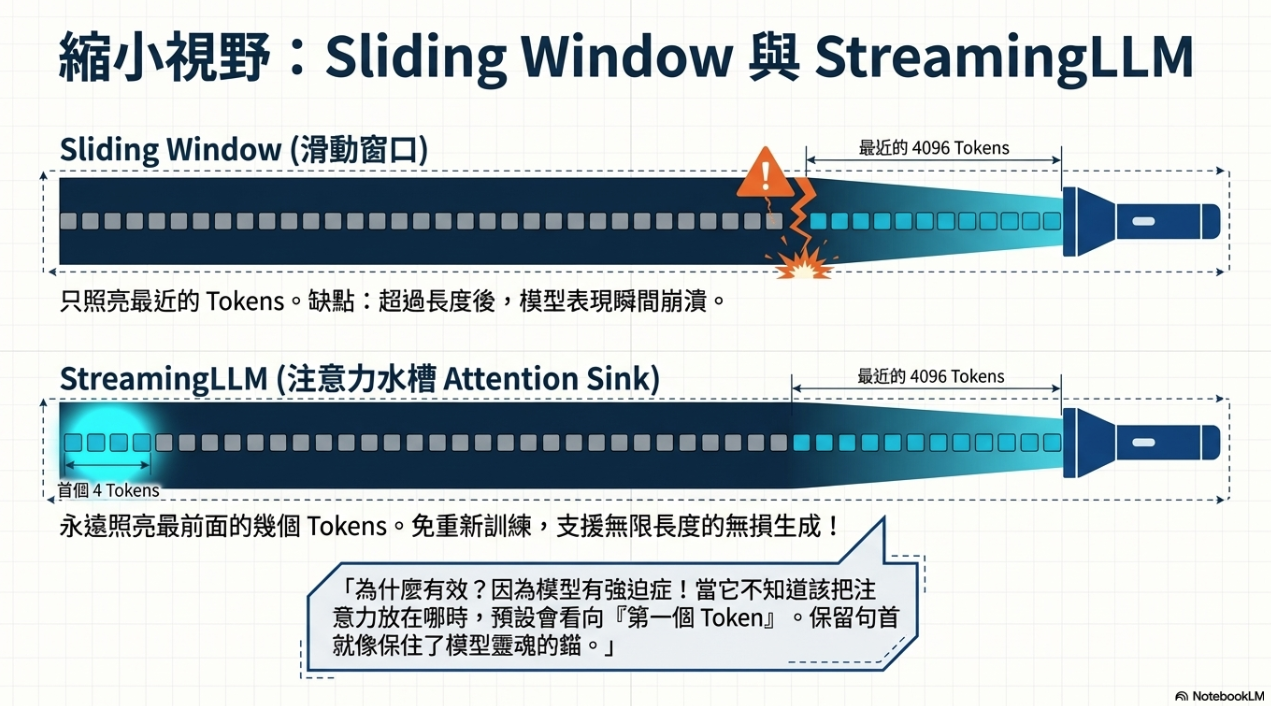
- Sliding Window Attention: 只關注固定長度的過去資訊,設定快取上限。
- Streaming LLM: 發現模型極度依賴序列開頭的幾個 token(Attention Sink),因此在滑動窗口中額外保留前幾個 token,即可在不訓練的情況下處理極長序列。
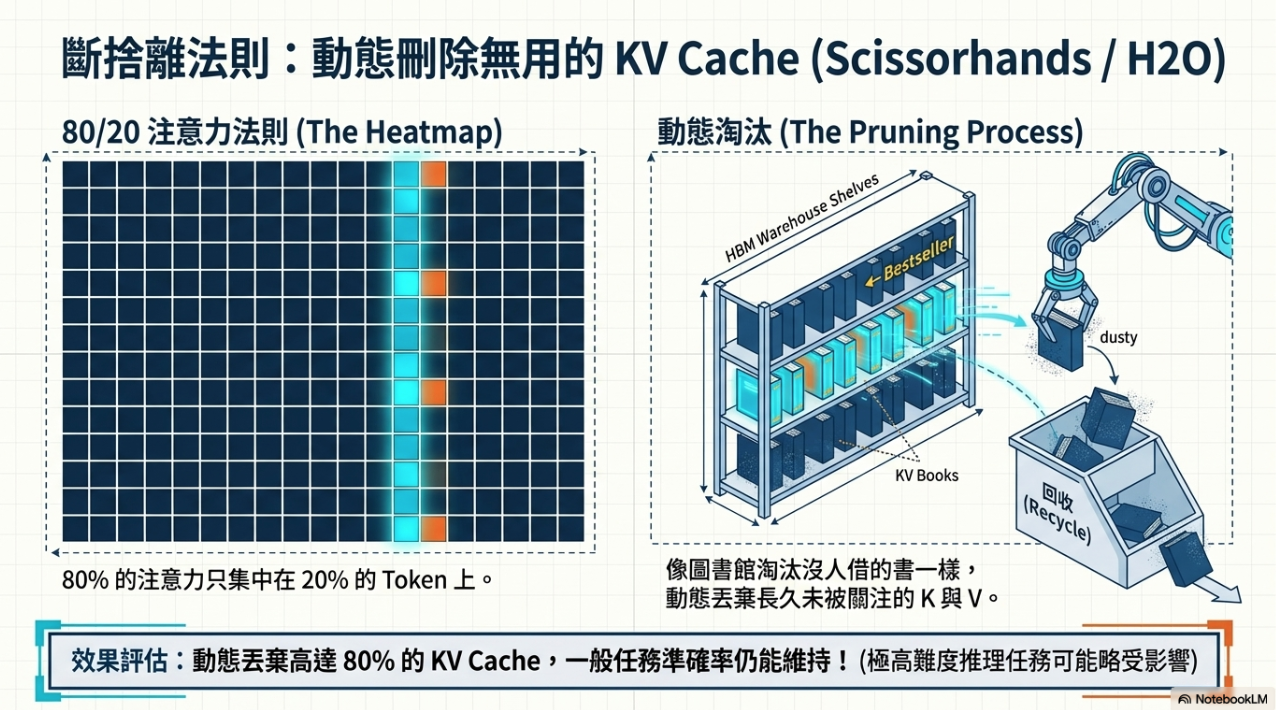
- KV Cache Pruning: 丟棄鮮少被關注的 $K$、$V$ 向量(如 H2O 演算法)。實驗證明,即便只保留 20% 的內容,在許多任務中表現依然良好。
結論:開發者的省錢建議¶
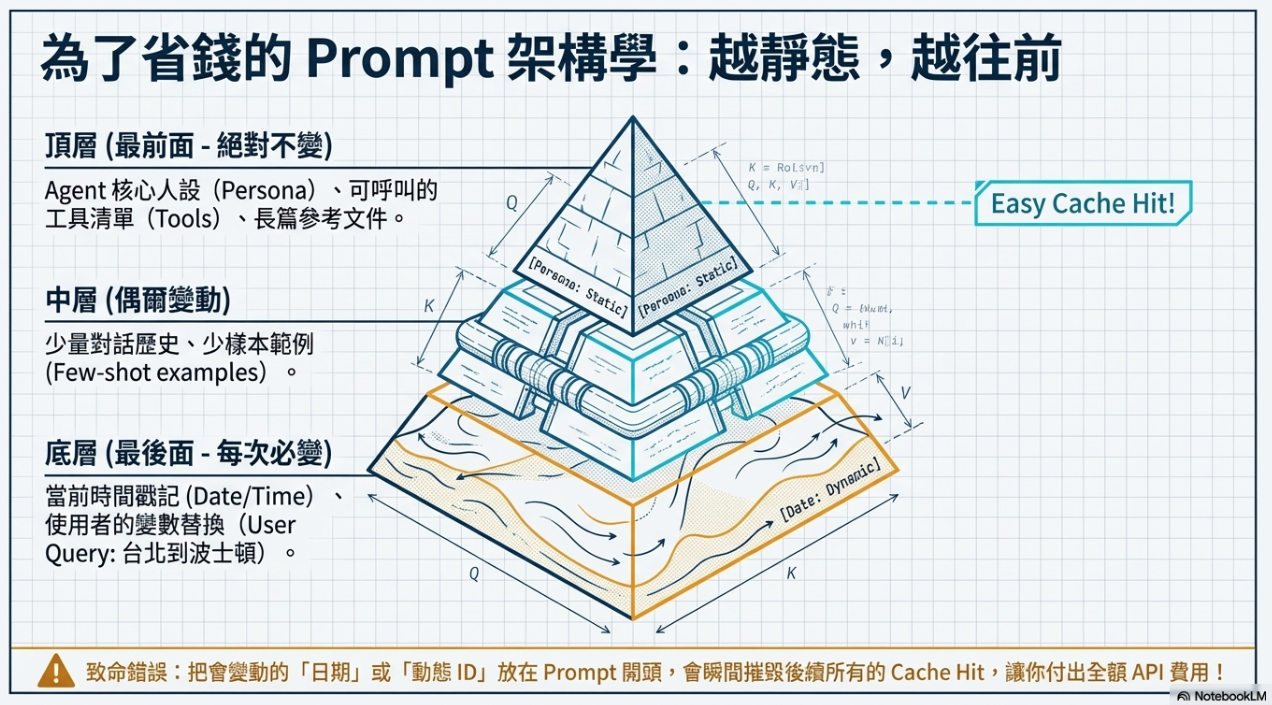
在設計 AI Agent 時,利用 Prefix Caching(前綴快取)能大幅降低成本:
- 規則: 將穩定不變的內容(如 System Prompt、工具說明)放在最前面,變動的內容(如日期、變數)放在最後面。
- 效益: 命中的快取部分通常有大幅折扣(如打一折),能節省超過 50% 的 API 費用。
Comments
Loading comments…
Leave a Comment