為什麼 Transformer 需要位置編碼?

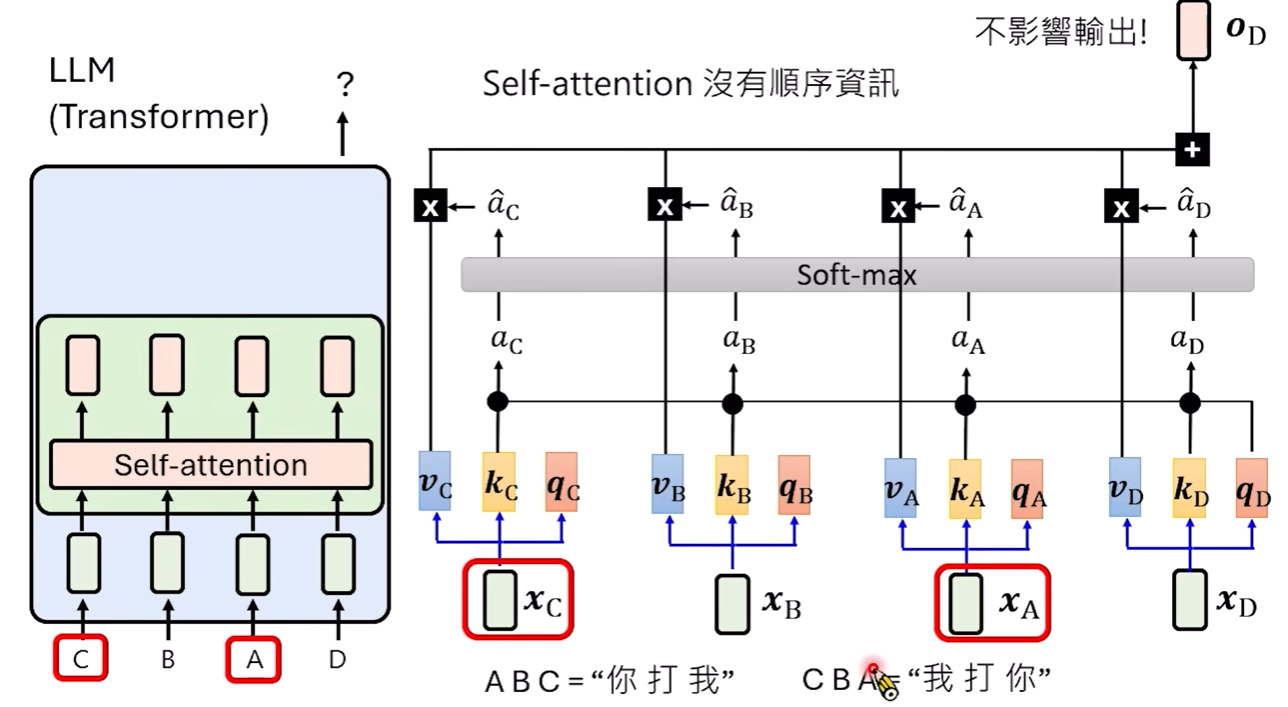
Transformer 的核心架構是 Self-attention(自注意力機制)。在原始的 Self-attention 計算過程中,無論輸入 Token 的順序如何對調,輸出的向量結果都是一樣的。這在語言理解上會造成嚴重的問題,例如「你打我」與「我打你」對模型而言將變得毫無差別。因此,我們必須引入「位置資訊」,讓模型知道每個 Token 所在的具體位置。從絕對到相對:位置編碼的演進
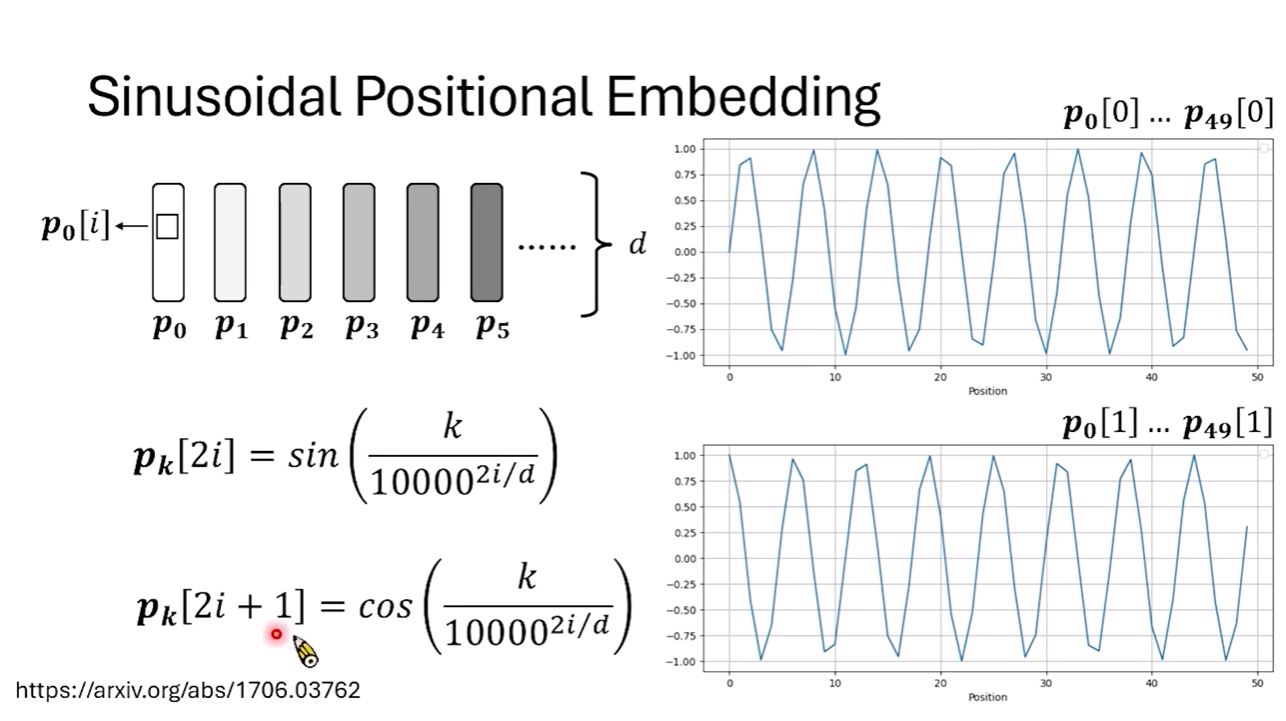
- 絕對位置編碼 (Absolute Positional Embedding):最早期的做法是為每個位置設計一個獨特的向量(如 P0, P1…),直接加在 Token 的 Embedding 上。最著名的設計是 Sinusoidal(正弦波)編碼,利用不同頻率的正弦與餘弦函數組成向量。其設計巧思在於,這讓模型有潛力透過線性轉換來理解 Token 間的「相對距離」。
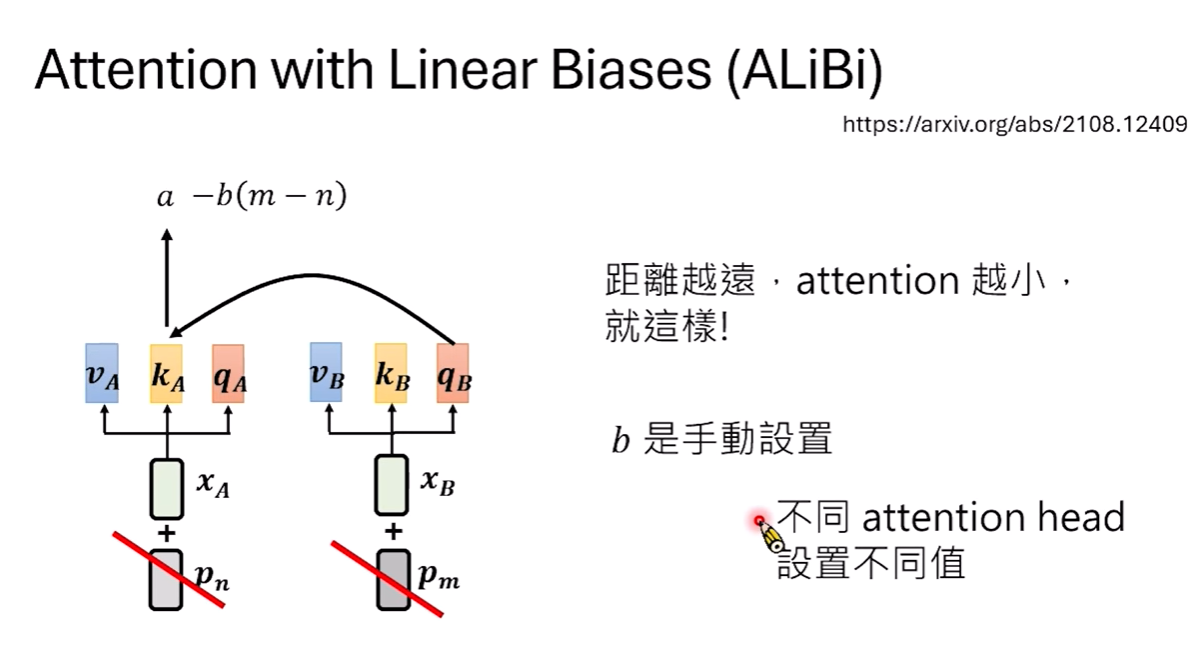
2. ALiBi (Attention with Linear Biases):研究發現,「相對位置」往往比絕對位置更重要。ALiBi 採取「簡單粗暴」的方法:不額外加位置向量,而是在計算 Attention 分數時,直接根據 Token 間的距離減去一個常數偏壓(Bias)。距離越遠,分數扣越多,這讓模型在處理比訓練時更長的序列時表現極佳。
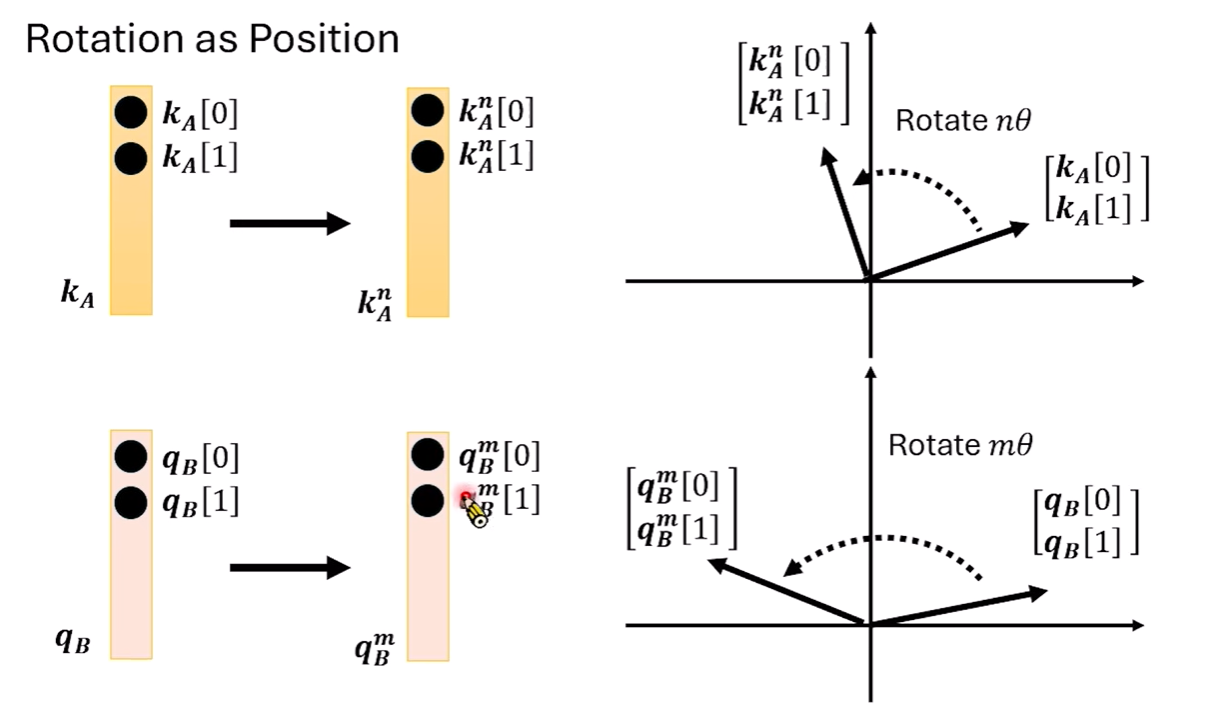
3. RoPE (Rotary Positional Embedding):這是目前 Llama、Qwen 等主流大模型採用的技術。RoPE 的核心概念是「旋轉」:它將位置資訊透過旋轉 Query (Q) 與 Key (K) 向量的方式注入。其數學特性保證了 Q 與 K 做內積(計算 Attention)時,結果僅取決於兩者的相對距離。此外,它與 KV Cache 及加速運算(如 Flash Attention)完全相容,是其流行的重要原因。
如何讓模型看更長?(長文本擴展技術)當我們希望模型處理超出訓練長度的序列時(Train Short, Test Long),RoPE 會面臨挑戰。影片中介紹了幾種擴展方案:
- 位置內插法 (Position Interpolation):將長序列的位置編號縮小(例如除以 2),使其落在模型看過的範圍內。
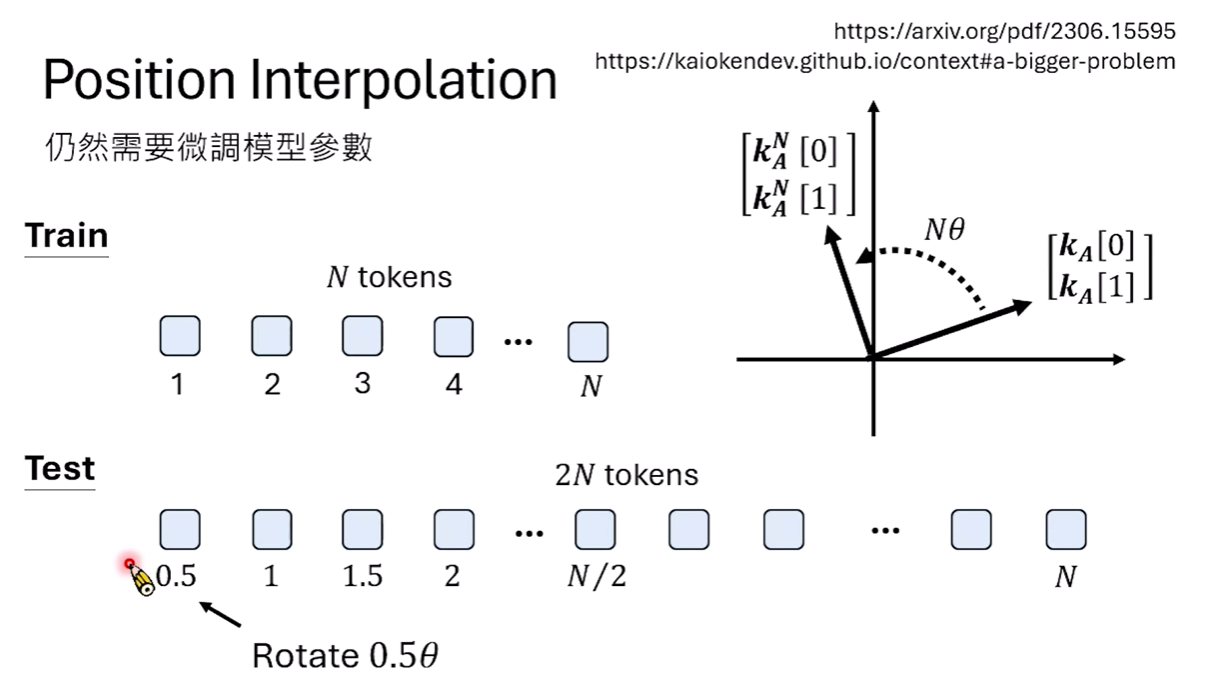
* NTK-aware scaling:一種根據頻率調整的策略,高頻部分(轉得快的指針)不動,低頻部分(轉得慢的指針)才做壓縮。
* YaRN 與 Dynamic Scaling:進一步優化不同頻率的縮放比例,或在推理時根據輸入長度動態調整,讓模型能處理多達 200 萬個 Token 的驚人長度。
靈魂拷問:我們真的需要位置編碼嗎?
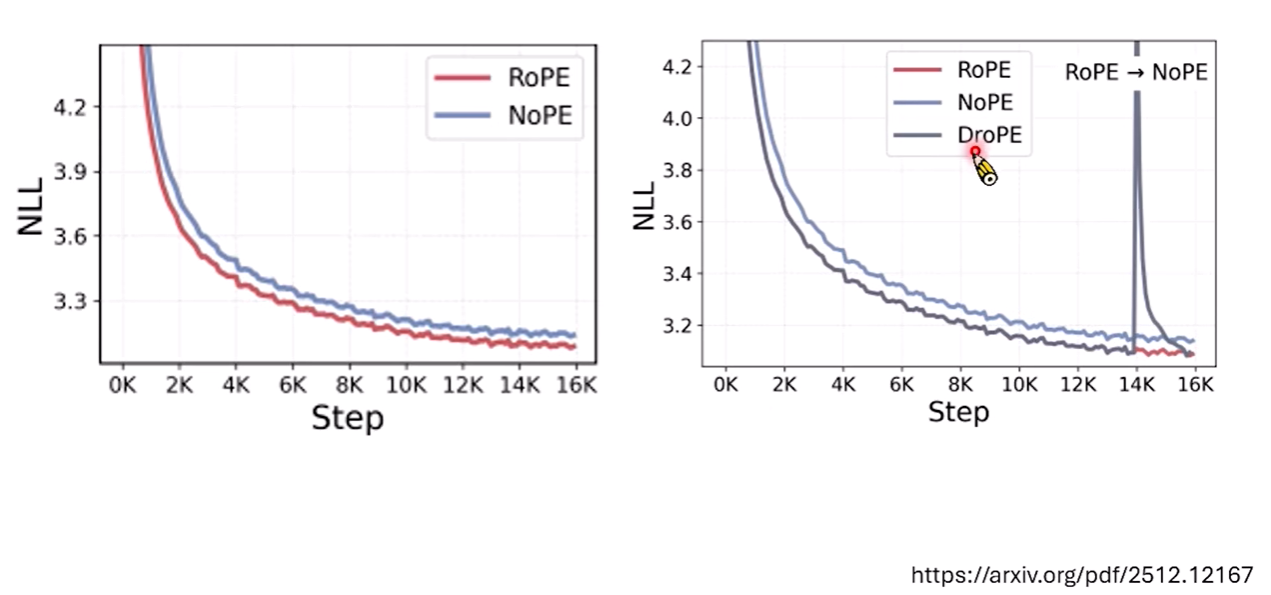
影片最後提到了一個令人驚訝的觀點:其實多層的 Self-attention 本身就隱含了位置資訊。研究顯示,完全不加位置編碼(NoPE)的模型,在某些任務上的外推能力甚至更好。然而,明確的位置編碼能顯著加速訓練過程並降低 Loss。因此,有研究提出 DropPos 方法:訓練時使用位置編碼來輔助模型學習,等到訓練快結束時再將其拔掉。這種「過河拆橋」的策略,反而能讓模型擺脫位置編碼的束縛,獲得更強的長文本處理能力。
Comments
Loading comments…
Leave a Comment